python request库发包百分号会自动url编码问题
最近在写批量扫描的poc的时候遇到了一个洞,需要get这个地址看看是否存在做验证
/setup/setup-s/%u002e%u002e/%u002e%u002e/log.jsp
最近在写批量扫描的poc的时候遇到了一个洞,需要get这个地址看看是否存在做验证
/setup/setup-s/%u002e%u002e/%u002e%u002e/log.jsp

这是一个空壳shell,可以通过上传LD_PRELOAD进行绕过,怎么判断要覆写的函数名?
可以通过看sh会调用的库函数
1 | └─$ sudo readelf -Ws /usr/bin/sh |

时间匆忙就做了一题还没有提交…
是一个经典的usb鼠标流量分析题了
下载题目拿到520个套娃zip,直接7z加连点器提取flag.png
然后放到Stegsolve.jar看到bgr通道里面有一个zip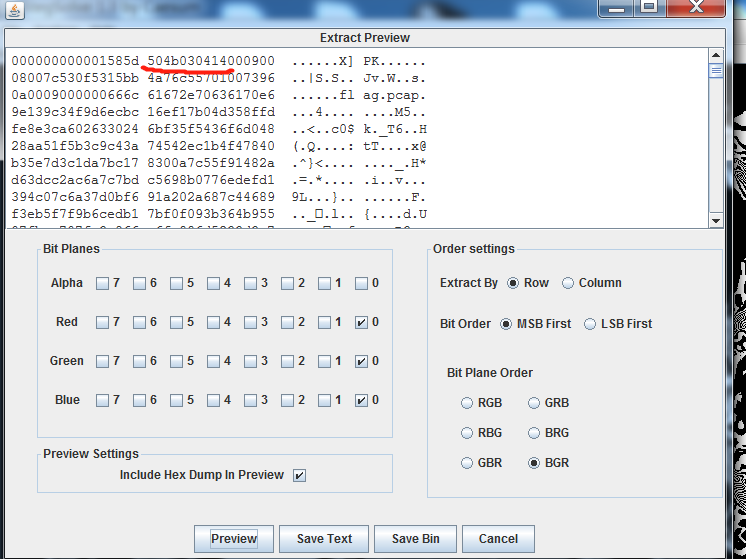
提取出来发现加密拿去爆破password:12345
又拿到pacp,打开看看是一个鼠标流量就用kali的工具提取一下数据
(USB协议的数据部分在Leftover Capture Data域之中,在Mac和Linux下可以用tshark命令可以将 leftover capture data单独提取出来 命令如下:
1 | tshark -r usb1.pcapng -T fields -e usb.capdata > usbdata.txt |
)
这里下载题目得到一张图片,hex观察无果,其他的隐写也无果。考虑题目的提示:刷新的按键一般是F5。故考虑F5隐写。
F5刷新隐写,原理文献:https://wenku.baidu.com/view/c9150e29b4daa58da0114a39.html,
利用工具:https://github.com/matthewgao/F5-steganography,
使用命令:java Extract 123456.jpg -p [password]/[空],在output.txt找解密后的文本,得flag。
2020ciscn’s wp: https://www.gem-love.com/ctf/2569.html
https://www.gksec.com/amp/CISCN2020_Online_WriteUp.html
2020gactf’s wp:https://mp.weixin.qq.com/s/7POuTp37wzY7bS3R-Fldog
misc: https://mp.weixin.qq.com/s/TXXyzswABUv4cLDOw5SdI
Crypto: https://mp.weixin.qq.com/s/c4bK2R_n_r5q_7rSidEuTg
WEB: https://mp.weixin.qq.com/s/H0-imfruCTIXtMG16a9CIA
钓鱼城杯量子加密misc题:
又到了周末,上网课是真的难受,今天就写写前几天做的题吧(由于我太菜,只做了几道misc)。(图太多了,懒得转移图床QAQ)

下载题目得到一个zip,解压得到一张图片。
先用010打开一下,发现尾部之后有一串base32编码。